Reading Notes: Probabilistic Model-Agnostic Meta-Learning
This post is a reading note for the paper "Probabilistic Model-Agnostic Meta-Learning" by Finn et al. It is a successive work to the famous MAML paper, and can be viewed as the Bayesian version of the MAML model.
Introduction
When dealing with different tasks of the same family, for example, the image classification family, the neural language processing family, etc.. It is usually preferred to be able to acquire solutions to complex tasks from only a few samples given the past knowledge of other tasks as a prior (few shot learning). The idea of learning-to-learn, i.e., meta-learning, is such a framework.
What is meta-learning?
The model-agnostic meta-learning (MAML) [1] is a few shot meta-learning algorithm that uses gradient descent to adapt the model at meta-test time to a new few-shot task, and trains the model parameters at meta-training time to enable rapid adaptation.
The idea is that we assume there are some tasks that are drawn from some distribution . For each task , we sample the data into two sets, and , where is used for training the model, and is for measuring whether or not the training was effective.
The MAML algorithm trains for few-shot generalization by optimizing for a set of initial parameters such that one or a few steps of gradient descent on a achieves good performance on . The objective function to optimize MAML is
,
where is used to denote the parameters updated by gradient descent and where the loss corresponds to negative log likelihood of the data.
Note that this objective function is different from the traditional learning objective functions in terms of
- There are 2 gradients to calculate for each updates, one from , and the other from ;
- The loss is calculated based on current parameter set plus , it essentially means the parameter of a model that is 1-step trained with .
Bayesian Meta-learning
When the end goal of few-shot meta-learning is to learn solutions to new tasks from small amounts of data, a critical issue that must be dealt with is task ambiguity: even with the best possible prior, there might be still not enough information from these few data points to resolve the new task with high certainty. Hence it is desirable to be able to sample multiple solutions with some uncertainty. Such a method could be used to evaluate uncertainty (by measuring agreement between the samples), perform active learning, or elicit direct human supervision about which sample is preferable.
The hierarchical Bayesian model
The hierarchical Bayesian is designed that includes random variables for the prior distribution over function parameters, , the distribution over parameters for a particular task, , and the task training and test datapoints.
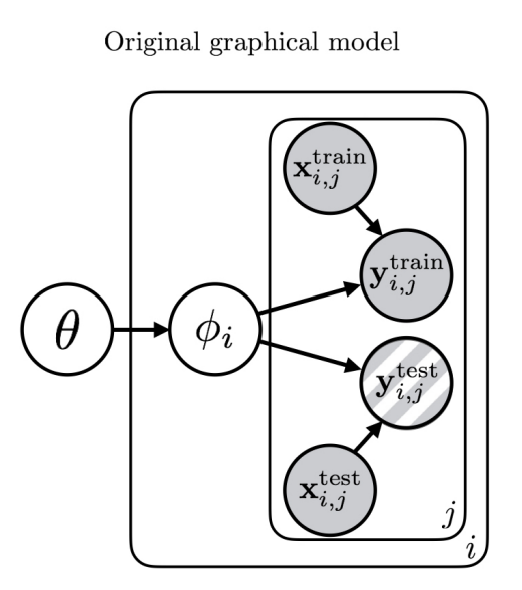
Fig 1: Hierarchical model with meta prior and task parameter .
Gradient-Based Meta-Learning with Variational Inference
One straightforward way is to combine meta-learning with variational inference. We approximate the distribution over the hidden variables and for each task with some distribution . And further rewrite it as . The variational lower bound on the log-likelihood can be written as
where and are neural inference network approximations to and .
These inference networks can be constructed by
However, in this approach, at the meta-test time, we must obtain the posterior , without access to . We can train a separate set of inference networks to perform this operation, potentially also using gradient descent within the inference network. However, these networks do not receive any gradient information during meta-training, and may not work well in practice.
Probabilistic Model-Agnostic Meta-Learning Approach with Hybrid Inference
MAML can be interpreted as approximate inference for the posterior
where is the maximum a posteriori (MAP) value. This can be viewed as the dependency network shown in Fig 2.
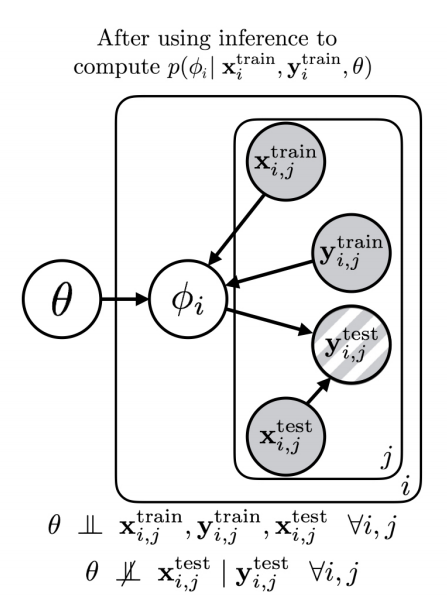
Fig 2: the dependency network after inference.
Thus, we can now write down a variational lower bound for the logarithm of the approximate likelihood, which is given by
Analogously to the previous section, the inference network is given by
At meta-test time, the inference procedure is much simpler. The test labels are not available, so we simply sample and perform MAP inference on using the training set, which corresponds to gradient steps on , where starts at the sampled . The procedure is described in Algorithm 1.

Algorithm 1: Probabilistic MAML
Adding additional dependencies
To remedy the crude approximation to , the authors propose additional dependencies in the dependency graph, as shown in Fig 3.
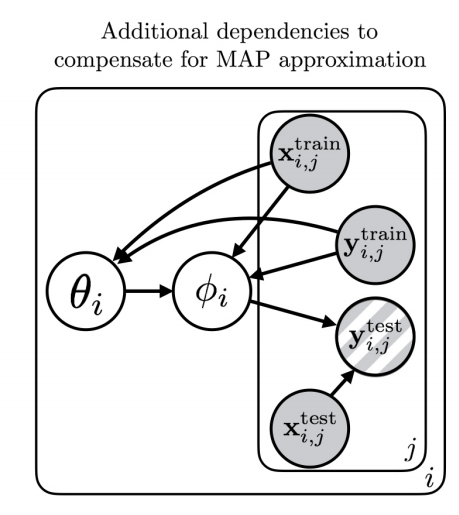
Fig 3: additional dependencies to compensate for MAP approximation.
Here is proposed to be dependent on and , the inference network can be constructed as
According to the experiments done by the authors, this more expressive distribution often leads to better performance. This meta-testing part is shown in Algorithm 2.

Algorithm 2: meta-testing part.
[1] Finn, Chelsea, Pieter Abbeel, and Sergey Levine. "Model-agnostic meta-learning for fast adaptation of deep networks." Proceedings of the 34th International Conference on Machine Learning-Volume 70. JMLR. org, 2017.
Comments
Post a Comment