Copulas as High-Dimensional Generative Models: Vine Copula Autoencoders
This post is a work through for this paper by Natasa et al: Copulas as High-Dimensional Generative Models: Vine Copula Autoencoders, one can find the paper here.
Introduction
The authors introduced vine copula autoencoder (VCAE) as a flexible generative model for high-dimensional distributions. The model is simply built in a three-step procedure:
- Train an autoencoder to compress the data into a lower dimensional representations;
- Estimate the encoded representation's distribution with vine copulas;
- Combine the distribution and the decoder to generate new data points.
The authors claimed that this generative model has 3 advantages compared to Generative Adversarial Nets (GANs) and Variational Autoencoders (VAEs):
- It offers modeling flexibility by avoiding most distributional assumptions in contrast to VAEs;
- Training and sampling procedures for high-dimensional data are straightforward;
- It can be used as a plug-in allowing to turn any AE into generative model, simultaneously allowing it to serve other purposes (e.g., denoising, clustering).
Vine copula autoencoders
The basic procedure of training vine copula autoencoders (VCAE) is described in Fig 1. The first building block of VCAE is a regular autoencoder, with a compressed latent representation . One major difference between VCAE and VAE is that VAEs assume a simple prior (like Gaussian) to , however, VCAEs doesn't make such assumptions, they deal with the distribution entirely with vine copula training.
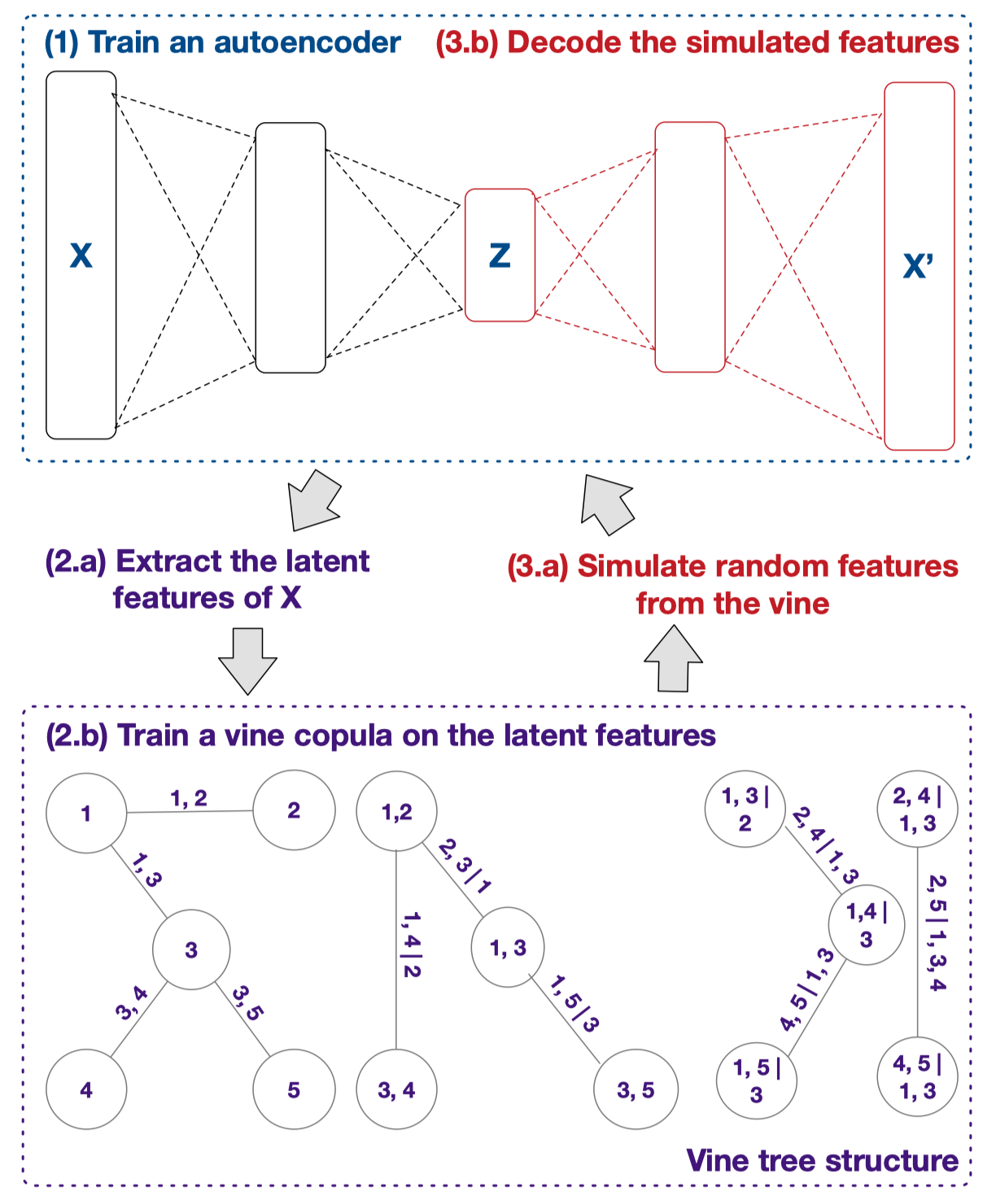
Fig 1: Conceptual illustration of a VCAE.
If we use to represent the autoencoder, then the job of vine copula is to learn the distribution of such that it can generate samples using .
Vine copulas
The major contribution lies in the application of vine copulas.
Copulas and its basic property
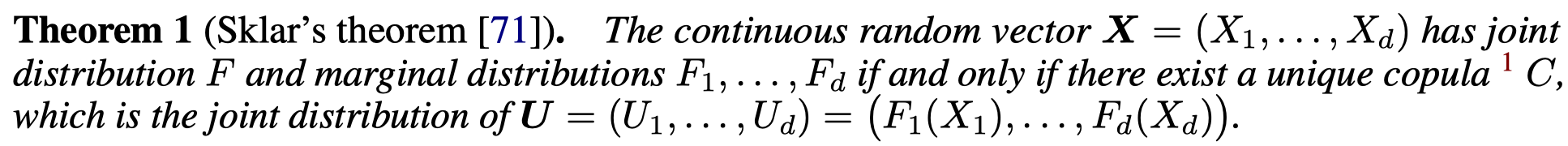
The Sklar's theorem tells us that copulas allow us to decompose a joint density into a product between the marginal densities and the dependence structure represented by the copula density . i.e., assuming that all densities exist, we can write , where and are the densities corresponding to respectively.
This implies that the generating procedure can be done in two steps:
- Estimating the marginal distributions;
- Using the estimated distributions to construct pseudo-observations via the probability integral transform before estimating the copula density.
Vine copulas construction
The pair-copula constructions (PCCs), also called vine copulas, is used in this paper as pair wise copula construction is much more feasible compared to joint modeling all variables.
PCCs model the joint distribution of a random vector by decomposing the problem into modeling pairs of conditional random variables, making the construction of complex dependencies both flexible and yet tractable.
Lets consider an example with 3 random variables , the joint density of can be decomposed as
Where s represents the marginal distributions of , and represents the pair copula between and , which also represents the dependencies. Note that represents conditional copula/dependency.
For the details of how vine copulas are estimated, or why they would work, one can read the workshop slides by Nicole et al. in NIPS workshop 2011.
The training and generating procedure of vine copula
Fig 2 illustrate the estimation and sampling procedure for a (conditional) pair copula.
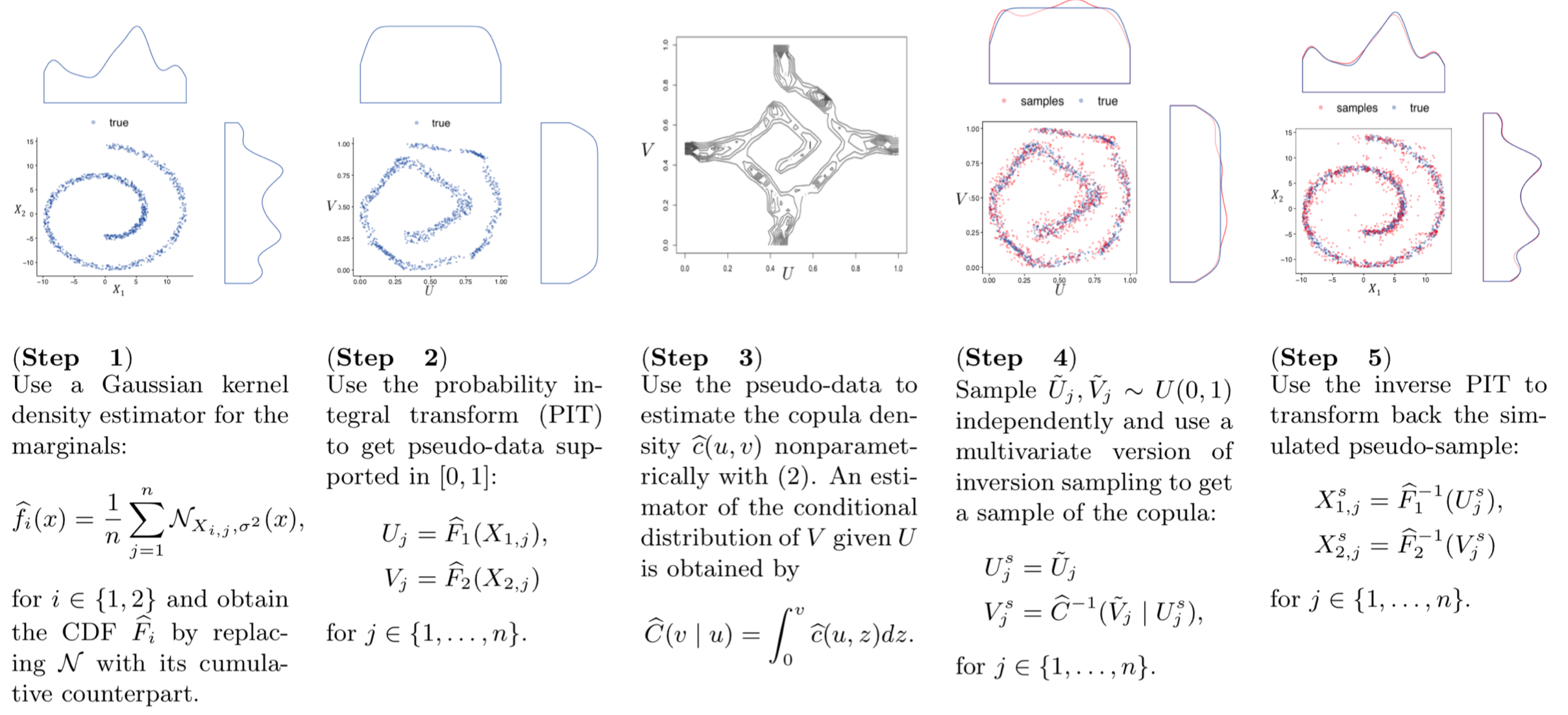
Fig 2: Estimation and sampling algorithm for a pair copula
Note that plenty of the algorithms for vine copula estimation and generation are implemented in C++ package vinecopulib.
Conclusion
The authors proposed a new way for deep generative modeling using vine copulas with a very clever combination of traditional vine copula estimation and a regular auto encoder modeling. This inspires us to apply more old-school techniques on the latent low-dimensional features learned by deep networks like autoencoders.
Comments
Post a Comment