Traditional collaborative filtering methods usually only incorporate user-item rating pairs for recommendation, the vast available metadata is just ignored in such scenario. With the recent rapid developments of deep learning techniques, neural based recommendation methods is emerging. Most of them benefit from the metadata that improves personalized recommendation significantly. This paper is an example that is based on neural architechture for recommendation with user reviews.





In this post, I just explain the model itself, for detail experiments and backgrounds, please refer to the original paper.
Problem Formulation
Inputs: User ID $a$, Item ID $b$, user $a$'s reviews set $\boldsymbol{d}_a= \{d_{a1},..., d_{al_a}\}$ and item $b$'s reviews set $\boldsymbol{d}_b= \{d_{b1},..., d_{bl_b}\}$.
Note that $\boldsymbol{d}_a$ contains all reviews given by user $a$, similarly, $\boldsymbol{d}_b$ contains all reviews received by item $b$.
Outputs: The predictred rating $\hat{r}_{ab}$ corresponding to user $a$ and item $b$.
Note that $\boldsymbol{d}_a$ contains all reviews given by user $a$, similarly, $\boldsymbol{d}_b$ contains all reviews received by item $b$.
Outputs: The predictred rating $\hat{r}_{ab}$ corresponding to user $a$ and item $b$.
The Model
The model is called multi-pointer co-attention network (MPCN). The full network is shown in Figure 1.
 |
| Figure 1: Multi-Pointer Co-attention Network, credit. |
It's a little bit complex, let's decompose and study it from the inputs to outputs, step by step.
Input Encoding
 |
| Figure 2: Input encoding |
As shown in Figure 2, the input encoding is a step to encode input list of reviews into an array of vectors. The maximum number of reviews for a user $a$ or item $b$ is set to be $l_r$, and each review consists of $l_w$ words which are represented by one-hot encoding, i.e. the $i$th word of the review is represented by one-hot vector $w_i$, hence a review can then be represented by $(w_1, ..., w_{l_w})$.
To encode reviews to vectors, as each word is a one-hot vector, a review's vector can be calculaterd by the sum of its constituent word embeddings. i.e.
\[x = \sum f_i w_i\]
where $f_i$ represents frequency of the corresponding word in the review.
The authors also state that not all reviews for a product are important. They apply Review Gating Mechanism to leverage the importance among different reviews by one user / for one product. i.e.
\[\bar{x}_i = \sigma(\boldsymbol{W}_gx_i) + \boldsymbol{b}_g \odot tanh(\boldsymbol{W}_u x_i + b_u)\]
This concludes the encoding.
Review-level Co-Attention
 |
| Figure 3: Review-level co-attention |
From the last section, assume the dimension of each review encoding is $d$, and because the maximum number of review for a user/ an item is $l_r$, then we have the review embeddings for user ($a\in R^{l_r \times d}$) and item ($b\in R^{l_r \times d}$). The co-attention matrix can then be calculated by
\[ s_{ij} = F(a_i)^T \boldsymbol{M} F(b_j)\]
where $\boldsymbol{M}$ is a $d\time d$ parameter matrix, $s_{ij}$ is the $(i,j)$ entry of co-attention matrix, and $F(\cdot)$ is a feed-forward neural network.
Pooling and Review Pointers
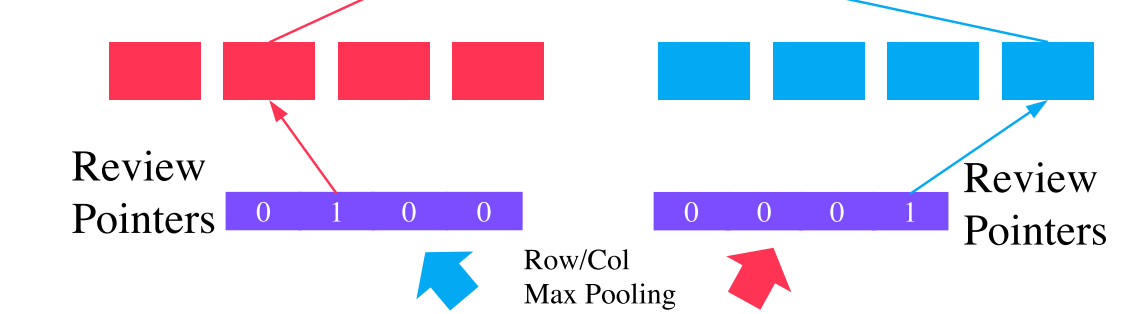 |
| Figure 4: Pooling and Review Pointers |
The idea here is that, by pooling operation, from the co-attention matrix, we want to get a one-hot vector as a review pointer, which point to the most important review for the user/item.
One may try with softmax and argmax (to produce one-hot vector). However, this approach is not good for this purpose as argmax will disable backpropagations. In this case, the authors propose to use Gumbel-softax function to replace softmax.
Gumbel-softmax enables descrete random variables (e.g. one-hot vectors) to be utilized within an end-to-end neural network architecture. In Gumbel-Softmax, the argmax function is replaced by the differentiable softmax function:

where τ, the temperature parameter, controls the extend of how much the output approaches a one hot vector. And $g$ are Gumbel noises.
In the forward pass, the one-hot vector is obtained via argmax:

However, the backward pass maintains the flow of continuous gradient using gumbel-softmax.
Hence the retrieved review vectors from the review pointers are calculated by
where $a'$ $b'$ are selected review vectors, G is the Gumbel-softmax, and $s$ is the co-attention matrix.
Word-level Co-Attention
The review-level co-attention smooths over word information as it compresses each review into a single embedding. However, the design of the model allows the most informative reviews to be ex- tracted by the use of pointers. These reviews can then be compared and modeled at word-level.
 |
| Figure 5: Word-level co-attention |
Let $\bar{a}$ and $\bar{b}$ be the selected reviews using the pointer learning scheme. Similar to the review-level co-attention, the co-attention matrix is computed word-by-word (not review-by-reviw):
\[w_{ij} = F(\bar{a}_i)^T \boldsymbol{M}_w F(\bar{b}_j)\]
Next, take the mean pooling (instead of max pooling in review co-attention) to get co-attentional representation of reviews $\bar{a}$ and $\bar{b}$:
Multi-Pointer Learning
All of the above discussions only include single pointer. The multi-pointer learning, indicated by its name, generate multiple pointers instead of one. with different Gumbel noise initializations, we can generate $n_p$ pointers of each review. In the word-level co-attention case, they are $\{\hat{a}_1',...,\hat{a}_{n_p}'\}$ and $\{\hat{b}_1',...,\hat{b}_{n_p}'\}$.
There are different aggregation methods can be used here to aggregate multiple pointers, the authors of this paper choose summation.
 |
| Figure 6: Aggregation multi-pointors by summation |
Prediction layer
The prediction layer is a factorization machine. Assume $a_f$ and $b_f$ are outputs from the previous layers, the FM function is defined as

Reference: Tay, Yi, Anh Tuan Luu, and Siu Cheung Hui. "Multi-pointer co-attention networks for recommendation." Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. ACM, 2018.
Six Line | This bet allows gamers to make two road bets . Doubling the width of the road, the payout for the six-line is just 5 to 1. Split | The cut up bet allows gamers to put a bet on two numbers that exist in neighboring pockets. Below we go even further into the different betting strategies out there in roulette and type of|what sort of} payouts may be 바카라사이트 expected from bets that hit during every spin.
ReplyDelete